


While DevOps focuses on the continuous development and deployment of code, MLOps adds data and models to the mix. In MLOps, you aren’t just tracking code changes; you are tracking “training-serving skew,” data drift, and model decay. If the data changes, the software performance changes—even if the code remains the same.
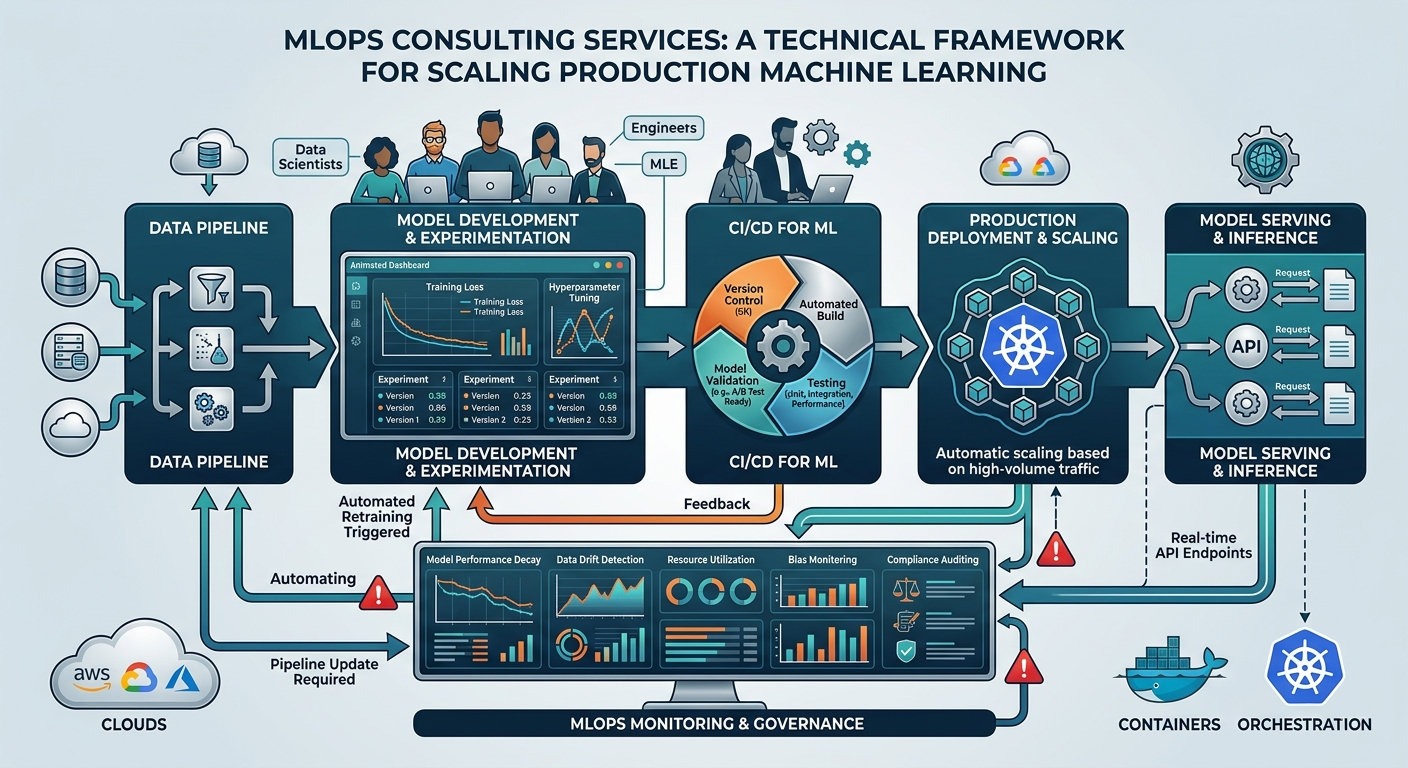
MLOps consulting services: A technical framework for scaling production machine learning
 16 minutes read
16 minutes read
Content
Sooner or later, every engineering organization running machine learning faces the dilemma: build the infrastructure to operationalize these models in-house, or bring in people who have experience doing this. The hesitation is not baseless – according to statistics, every second AI project fails to make it from prototype to production, and badly set infrastructure – pipelines, deployment processes, monitoring, and governance – is the reason.
This guide breaks down what MLOps consulting actually delivers, how to assess where your organization stands today, and how to structure an engagement that produces infrastructure your team owns long-term.
What are MLOps consulting services?
MLOps – short for Machine Learning Operations – applies the principles of DevOps to the machine learning lifecycle. Where DevOps manages software releases, MLOps services manage the full pipeline from raw data to a model serving predictions in production.
MLOps consulting services are engagements in which external specialists design, build, or improve the pipeline for your organization. The scope typically spans:
- Infrastructure architecture: selecting and configuring the tools that run your pipelines
- Pipeline automation: eliminating manual steps in training, validation, and deployment
- Monitoring and observability: detecting when model performance degrades before it affects business outcomes
- Governance and compliance: ensuring models are auditable, reproducible, and aligned with regulatory requirements
MLOps consulting is not data science. MLOps services consultants in this space don’t generally build your models; they build the systems that make those models reliable, repeatable, and maintainable at scale.
Why does it matter to the business? Without MLOps infrastructure, every new model deployment is a manual, high-risk event. Teams re-solve the same engineering problems repeatedly, models drift silently in production, and the cost of each iteration compounds. A well-structured MLOps practice turns one-off deployments into a repeatable capability.
The MLOps maturity model: Assessing your infrastructure
Before choosing tools or hiring consultants, you need an honest read on where your organization stands at the moment. The MLOps maturity model provides that baseline. It describes three levels of operational sophistication, each with a distinct cost profile, risk exposure, and ceiling on how fast your team can ship.
You define what level our business actually needs, and what the cost of staying where you are at the moment is.
Level 0: Manual
At Level 0, ML workflows are largely script-driven and human-dependent. Data scientists train models locally, hand off artifacts to engineering teams, and deployments happen through ad hoc processes, often involving manual file transfers, undocumented environment configs, and tribal knowledge.
Characteristics:
- No pipeline automation; each training run is triggered manually
- Models are rarely retrained after initial deployment
- No systematic monitoring for drift or degradation
- Experiment tracking, if it exists, lives in spreadsheets or notebooks
- Deployment is a one-off event, not a repeatable process
Level 0 is viable for organizations running one or two low-stakes models infrequently. It becomes a liability the moment you need to update models regularly, operate multiple models in parallel, or demonstrate reproducibility for audit or compliance purposes. The hidden cost is engineer time, as every deployment pulls senior people into manual coordination work.
Level 1: Automated pipeline
At Level 1, the training pipeline is automated end-to-end. Data ingestion, preprocessing, training, evaluation, and model registration happen without manual intervention, triggered either on a schedule or by data events. The model artifact that enters production is the direct output of a versioned, reproducible pipeline.
Characteristics:
- Automated retraining triggered by schedules or data thresholds
- Feature stores or structured feature engineering pipelines are in place
- Experiment tracking with versioned datasets, parameters, and metrics
- Model registry manages artifact lineage and promotion gates
- Monitoring covers basic performance metrics and data distribution shifts
Level 1 is a target for most production ML teams. It removes the bottleneck of manual retraining, reduces deployment risk through reproducibility, and gives leadership visibility into model performance over time. Most organizations working with an MLOps consultant are moving from Level 0 to Level 1. This transition delivers the highest return relative to investment.
Level 2: CI/CD automation
Level 2 extends automation into the deployment and validation layer itself. Model updates move through a formal CI/CD pipeline: automated testing, staged rollouts (canary or blue/green deployments), and rollback triggers based on live performance signals. The pipeline itself –not just the model – is under version control and continuously tested.
Characteristics:
- Full CI/CD pipeline for both model code and infrastructure
- Automated A/B testing and staged deployment with statistical guardrails
- Shadow mode and canary deployments to validate models before full traffic exposure
- Automated rollback on performance degradation signals
- Pipeline components are modular, reusable, and independently deployable
Level 2 of MLOps services is appropriate for organizations where ML is a core product differentiator, where the cost of a bad model update is high, and deployment frequency is weekly or faster.
A consultant’s first job is typically to place your organization accurately on this model. Not where you aspire to be, but where your processes, tooling, and team actually operate today. That audit prepares the basis and defines the direction for everything that follows.
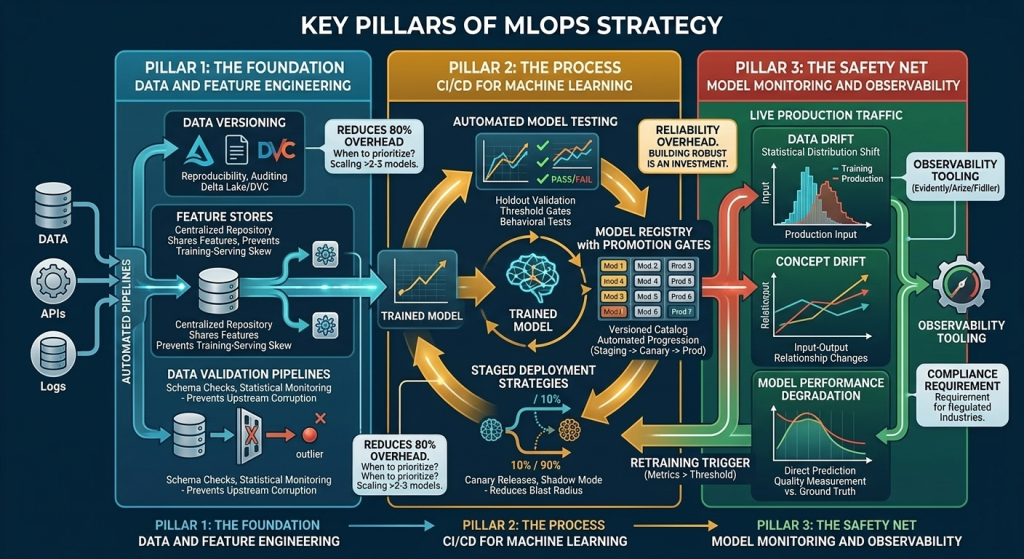
Key pillars of MLOps strategy
A durable MLOps strategy rests on three functional areas. Each one is addressable independently, but most effective when designed together. Gaps in any one of them tend to surface as production failures, cost overruns, or compliance exposure.
The foundation: Data and feature engineering
This pillar covers how raw data is ingested, transformed, validated, and made available for training and inference – consistently, at scale, and with full lineage.
The core components:
- Data versioning: Tracking which dataset a model was trained on, so results are reproducible and audits are traceable. Tools like DVC or Delta Lake handle this at the storage layer.
- Feature stores: Centralized repositories where engineered features are computed once and shared across models. This eliminates redundant computation and, more importantly, prevents training-serving skew: the condition where features computed differently at training time versus inference time silently degrade model performance.
- Data validation pipelines: Automated schema checks and statistical distribution monitoring that catch upstream data quality issues before they reach model training. Without this, a schema change in a source system can corrupt a retraining run with no visible error.
Feature engineering typically consumes up to 80% of a data scientist’s time on any given project. A well-architected feature store with reusable, validated features compresses that overhead significantly on every subsequent model. It also reduces the risk that two teams independently compute the same feature differently – a common source of inconsistent model behavior across products.
When to prioritize this first? When your organization runs more than two or three models, or if different teams share data sources, invest in this layer before scaling anything else.
The process: CI/CD for machine learning
Software CI/CD automates the path from code commit to production deployment. ML CI/CD does the same, but the artifact being tested and deployed is a trained model, not a software binary. That distinction introduces complexity that standard DevOps pipelines don’t account for.
A production-grade ML CI/CD pipeline includes:
- Automated model testing: Beyond unit tests on code, this means validation against holdout datasets, performance threshold gates, and behavioral tests (does the model still perform adequately on known edge cases?).
- Model registry with promotion gates: A versioned catalog where models move through stages (staging, canary, production) based on automated evaluation criteria, not manual approval alone.
- Staged deployment strategies: Canary releases expose new models to a fraction of live traffic before full rollout. Shadow mode runs a new model in parallel with the production model, comparing outputs without serving them to users. Both reduce the blast radius of a bad model update.
- Automated rollback: Predefined performance thresholds that trigger an automatic reversion to the previous model version if a new deployment degrades key metrics.
Manual deployment processes are slow and error-prone. More critically, they don’t scale. Each new model or update cycle requires the same engineering coordination overhead. CI/CD automation converts deployment from a project into a routine operation, compressing cycle time and freeing engineering capacity for higher-value work.
There is a trade-off: building a robust ML CI/CD pipeline requires upfront investment in the form of several weeks of engineering time and meaningful infrastructure cost.
The safety net: Model monitoring and observability
A model that performs well at launch will not necessarily perform well six months later. Data distributions can shift, user behavior changes frequently, and upstream systems evolve. A systematic monitoring allows you to spot model degradation before it surfaces as a business problem, reflecting conversion rates, fraud losses, and the amount of customer complaints.
A production monitoring stack addresses three distinct failure modes:
- Data drift: The statistical distribution of input features in production diverges from the training distribution. The model is being asked to make predictions on data it hasn’t seen before.
- Concept drift: The relationship between inputs and the correct output changes over time. A fraud detection model trained pre-pandemic may classify post-pandemic transaction patterns differently than a human reviewer would.
- Model performance degradation: Direct measurement of prediction quality against ground truth labels, where ground truth is available with an acceptable lag.
Observability tooling – platforms like Evidently, Arize, or Fiddler – automates the detection of these signals and routes alerts to the appropriate teams before degradation becomes a customer-facing event.
Monitoring infrastructure is also the mechanism by which retraining is triggered in a mature pipeline. Rather than retraining on a fixed schedule, a well-instrumented system retrains when drift metrics cross defined thresholds, reducing unnecessary compute while ensuring models stay current.
For organizations operating in regulated industries such as financial services, healthcare, and insurance, model monitoring logs are increasingly a compliance requirement. Regulators expect evidence that model behavior is being tracked over time and that degradation triggers a defined response process.
These three pillars are highly interactive. A feature store without data validation is a single point of failure. A CI/CD pipeline without monitoring has no feedback loop. Monitoring without reproducible pipelines can detect a problem, but can’t efficiently fix it. The MLOps as a service consultant’s role is not assembling them as independent tools, but designing these components as a system.
Why hire an MLOps consultant?
Most engineering teams can build MLOps infrastructure. The main question is whether the time, iteration cost, and organizational risk of building MLOps solutions from scratch are the right use of your team’s capacity. Let’s take a look at the problem and the solution.
4 out of 5 ML models never reach production
The models stall in production pipelines for predictable reasons: infrastructure that wasn’t designed for ML workloads, deployment processes that require too much manual coordination, monitoring gaps that make stakeholders reluctant to trust live model outputs, and data pipelines that work in a notebook but break under production load.
These are solved problems. The organizations that have crossed this threshold have left behind reusable patterns, tooling decisions, and failure postmortems. Consultants carry that accumulated knowledge into your environment, which is the core of the value proposition.
Production-ready templates for quicker deployment
A consultant engagement typically begins with infrastructure that already works – pipeline templates, infrastructure-as-code modules, CI/CD scaffolding – adapted to your stack rather than built from zero. That starting point changes the timelines.
An internal team building the same MLOps solutions infrastructure for the first time will spend lots of time on tooling evaluation, integration failures, and undocumented edge cases. A consultant who has implemented the same patterns across multiple environments has already absorbed that cost.
Who benefits the most?
- Organizations with a hard deadline on a model launch
- Teams where data scientists are currently absorbing infrastructure work
- Businesses that have already attempted an MLOps build internally and stalled
Cost efficiency issue
Inefficiently run ML workloads cost the company a lot. Training jobs, inference endpoints, and data processing pipelines consume compute continuously, and default configurations rarely focus on cost optimization.
Two levers can change the situation:
- Auto-scaling inference: Serving infrastructure that scales down during low-traffic periods and scales up on demand, rather than maintaining peak-capacity instances continuously.
- Spot instance orchestration: Routing fault-tolerant training jobs to preemptible compute at a fraction of on-demand pricing, with automatic checkpointing to handle interruptions.
Infrastructure inefficiency is one component; another is engineer time. When senior engineers spend cycles on manual deployment coordination or debugging undocumented pipeline failures, that cost doesn’t show up in a cloud bill, but it exists.
Consultant-built infrastructure that your team doesn’t have to maintain at the plumbing level returns that capacity to product work.
Selecting the right stack: Tools and technologies
The right stack is the one your team will actually maintain, not the one with the most promising capabilities. A consultant’s role in this phase is to match tooling to your team’s existing skills, your deployment environment, and your operational capacity. Then, to document the decision rationale so that future choices are made consistently. Let’s take a look at different groups of tools.
Orchestration
Orchestration tools manage the sequencing, scheduling, and retry logic of pipeline steps – training runs, data validation jobs, model evaluation, and deployment triggers.
- Apache Airflow remains the default for organizations already running data engineering pipelines. Familiarity and ecosystem breadth are its primary advantages; ML-native features are limited.
- Kubeflow Pipelines is built for Kubernetes-native environments and handles ML-specific concerns (GPU scheduling, artifact lineage) more naturally. Higher operational overhead to run and maintain.
- Prefect and Dagster offer a middle path. They are more developer-friendly than Airflow, but less infrastructure-intensive than Kubeflow. Both have grown their ML ecosystem integrations meaningfully in recent years.
Tracking
Experiment tracking tools log parameters, metrics, and artifacts across training runs, making results reproducible and comparable.
- MLflow is the most widely deployed open-source option. It integrates with most major frameworks and cloud platforms, and its model registry provides a lightweight promotion workflow.
- Weights & Biases (W&B) offers a richer interface and stronger collaboration features, with a managed hosting option that reduces operational burden. Better fit for teams running high volumes of experiments where visualization and sharing matter.
- Neptune.ai occupies similar territory to W&B with a focus on metadata management at scale.
Serving
Model serving infrastructure handles inference – receiving requests, running predictions, and returning results at the latency and throughput your application requires.
- BentoML and Ray Serve both support multi-model serving and are framework-agnostic, making them well-suited for organizations running heterogeneous model types.
- TorchServe and TensorFlow Serving are tightly coupled to their respective frameworks – lower configuration overhead if you’re standardized on one, a constraint if you’re not.
- Managed options – SageMaker Inference, Vertex AI, Azure ML endpoints – trade configuration flexibility for operational simplicity. Often, the right call for teams without dedicated MLOps engineering capacity.
Implementation roadmap: How to start
Step 1: Discovery and audit
Before introducing any tooling, a consultant needs an accurate picture of your current state. This phase produces a baseline assessment, not a sales pitch for a larger engagement.
What gets examined:
- Existing data pipelines – how data moves from source systems to model training, where manual steps live, and where failures occur
- Current deployment process – how models reach production today, who is involved, and how long it takes
- Monitoring and alerting coverage – what is currently measured, what is invisible
- Team structure and skill distribution – who owns what, where capacity constraints are, and where infrastructure work is currently absorbing data science time
Step 2: MVP pipeline setup
The MVP phase of MLOps consulting services focuses on the highest-leverage improvements, typically automating the training pipeline, introducing experiment tracking, and establishing a model registry with basic promotion gates. The goal is a repeatable, documented path from data to a deployed model, replacing the most manual and error-prone steps in your current process.
Typical deliverables:
- Automated retraining pipeline connected to your data sources
- Experiment tracking configured and integrated with existing workflows
- Model registry with staging and production environments
- Basic data validation checks at pipeline entry points
- Deployment automation for at least one production model
It’s not a complete Level 2 CI/CD system. Shadow deployments, canary releases, and full monitoring coverage come later.
Step 3: Scaling and governance
With a working baseline in place, this phase extends coverage and adds the controls required by regulated industries and larger engineering organizations.
Scaling priorities:
- Expanding pipeline automation to additional models and teams
- Implementing auto-scaling inference and spot instance orchestration for cost efficiency
- Adding staged deployment strategies (canary, shadow mode) where model update risk justifies the infrastructure
- Building out drift detection and automated retraining triggers
Governance priorities:
- Model lineage documentation – full traceability from raw data to production artifact
- Access controls and audit logging on the model registry and pipeline actions
- Incident response runbooks for model degradation events
- Knowledge transfer – ensuring your internal team can operate, extend, and debug the infrastructure without ongoing consultant dependency
At the close of this phase, your team should be able to retrain and deploy a model without external involvement, diagnose a monitoring alert without escalating to the consultant, and onboard a new model to the pipeline without rebuilding infrastructure from scratch.
Summary and next steps
MLOps consulting delivers the most value when it’s scoped as an infrastructure investment, not a service dependency. The organizations that get the most out of these engagements treat the consultant as a builder and knowledge transfer partner, leaving with systems their teams own and can extend, not a black box that requires ongoing external maintenance.
If your company is evaluating MLOps infrastructure investment, the right starting point is a structured audit of your current state. Blackthorn Vision has hands-on experience providing MLOps consulting services. We implement MLOps pipelines across most industries, including regulated ones such as finance and healthcare. We are experienced with every step, from Level 0 to production-grade CI/CD systems.
We help you assess where you are, scope what’s worth building, and deliver infrastructure your team will own long after the engagement ends.
FAQ
What is the difference between DevOps and MLOps?
Does MLOps replace Data Scientists?
Not at all. MLOps empowers Data Scientists. By automating the “plumbing” (data ingestion, infrastructure provisioning, and monitoring), Data Scientists can focus on what they do best: building better algorithms and extracting insights, rather than managing server clusters.
How do we measure the ROI of MLOps consulting?
Success is typically measured by four key metrics:
- Time-to-Market: How quickly can a new model go from an idea to a production API?
- Reliability: Reduction in system downtime caused by data or model errors.
- Scalability: The ability to manage 100 models with the same head-count previously required for 5.
- Compliance: Having a clear audit trail for data usage and model decisions.
Which cloud providers or tools do you support in this framework?
A robust technical framework is usually cloud-agnostic. Whether your stack is built on AWS (SageMaker), Google Cloud (Vertex AI), Azure ML, or open-source tools like Kubeflow and MLflow, the core principles of data versioning, feature stores, and model monitoring remain the same.
How does MLOps help in reducing Technical Debt?
Technical debt in ML often manifests as “spaghetti” data pipelines or undocumented manual steps. A technical framework introduces Automated CI/CD for ML, which ensures every model is versioned, reproducible, and tested before hitting production. This prevents the “black box” syndrome where only one data scientist knows how a model works.
At what stage of growth should a company invest in MLOps consulting?
You should consider MLOps services when you move from “Experimental ML” (notebooks and manual deployments) to “Production ML.” If your team is spending more than 30% of their time manually fixing pipelines or if you have no clear way to audit why a model made a specific prediction, it’s time to implement a formal framework.
You may also like
-
 April 3, 2026Read in 31 min.
April 3, 2026Read in 31 min.AI software development services: A complete guide for business leaders and decision-makers
Transform your business with expert AI software development services. We build custom GenAI, machine learning, and autonomous agent solutions tailored for enterprise ROI. Get a free consultation today! -
 April 1, 2026Read in 17 min.
April 1, 2026Read in 17 min.The strategic hub: Why global leaders choose software development outsourcing in Ukraine
Why global leaders choose software development outsourcing in Ukraine. Explore the top 10 IT companies, specialized tech stacks, and how to scale your business with a dedicated Ukrainian development team. -
 March 31, 2026Read in 19 min.
March 31, 2026Read in 19 min.Selecting the best Java development companies
Leading Java development companies. Analyzes top-tier Java software development services, evaluation criteria, and delivery models to help you find the perfect strategic partner for scalable enterprise solutions -
 March 31, 2026Read in 14 min.
March 31, 2026Read in 14 min.Top progressive web app development companies
Partner with a leading progressive web application development company. Explore our list of top PWA developers in the USA and globally, offering high-speed, offline-ready, and SEO-friendly web app solutions -
 March 23, 2026Read in 23 min.
March 23, 2026Read in 23 min.Why data warehouses fail and how to design one that doesn’t
top building data swamps. Explore the evolution of DWH design, including ELT workflows, Data Vault 2.0, and high-performance cloud modeling strategies -
 March 18, 2026Read in 13 min.
March 18, 2026Read in 13 min.Choosing React Native app development company
Partner with a premier react native development company. Compare the top 10 firms offering elite react native app development services for high-performance apps. -
 March 17, 2026Read in 15 min.
March 17, 2026Read in 15 min.Choosing the Right Computer Vision Development Company for Your Project
From computer vision consulting to full-scale software development, learn how modern vision systems automate defect detection and optimize operations across healthcare, retail, and manufacturing. -
 March 16, 2026Read in 12 min.
March 16, 2026Read in 12 min.AI in data governance: Everything technology leaders need to know
Master Data Governance for AI. Learn how to manage data drift, bias mitigation, and active metadata using NIST standards. Expert guide on MLOps, RAG security, and EU AI Act compliance for 2026. -
 March 12, 2026Read in 12 min.
March 12, 2026Read in 12 min.Choosing your generative AI development company
Compare the best generative AI companies for your enterprise. From custom LLMs to agentic workflows, discover the top partners driving innovation and ROI in the AI-first era. -
 March 6, 2026Read in 15 min.
March 6, 2026Read in 15 min.PyTorch vs TensorFlow: What’s the difference and which one wins
Stop choosing between research and production. Learn how Keras 3 and multi-backend architectures are unifying the AI ecosystem. A professional developer’s deep dive into performance, cost, and scalability. -
 March 5, 2026Read in 15 min.
March 5, 2026Read in 15 min.Choosing the best MVP development companies
Top-rated agencies providing bespoke MVP software development services to help startups validate ideas and scale fast -
 March 4, 2026Read in 19 min.
March 4, 2026Read in 19 min.Top software testing companies: Leading QA partners
Leading software testing companies. Compare top QA service providers, evaluation criteria, and industry trends to find your ideal partner. -
 February 28, 2026Read in 22 min.
February 28, 2026Read in 22 min.Top 10 software development companies in the USA
Find the best US-based software developers. From AI to enterprise web apps, here are the top 10 software development companies in the USA you should hire in 2026. -
 February 25, 2026Read in 12 min.
February 25, 2026Read in 12 min.Top 10 Node.js Development Companies
Industry's leading Node.js development companies. Our deep-dive review covers technical maturity, cloud-native expertise, and architectural standards to help you find the perfect software partner. -
 February 23, 2026Read in 16 min.
February 23, 2026Read in 16 min.Top 10 mobile application development companies: Selection & industry leaders
Top 10 mobile application development companies for your next project. Compare top-rated mobile app developers, explore custom app development company profiles, and learn the secrets to a successful technical partnership. -
 February 23, 2026Read in 12 min.
February 23, 2026Read in 12 min.How to choose the best Android app development agency: Rankings & selection criteria
Compare the leading Android development companies. Our guide highlights the top 10 firms for enterprise architecture, security, and custom app engineering. -
 February 19, 2026Read in 18 min.
February 19, 2026Read in 18 min.IT Managed Service Providers (MSPs): Why does your business need one?
Stop guessing. Compare the 10 leading IT Managed Service Providers (MSPs) for any-sized companies. Find proven security, cloud, and 24/7 support. View the comparison! -
 February 19, 2026Read in 45 min.
February 19, 2026Read in 45 min.Top 30 software development companies: Categories, red flags, and the selection strategy
We’ve analyzed the top 30 software development companies based on expertise, client results, and innovation. Find your ideal match here! -
 February 11, 2026Read in 18 min.
February 11, 2026Read in 18 min.Top 10 Cloud migration companies: Strategic architecture of cloud migration
Compare the top 10 cloud migration companies based on architectural depth, FinOps integration, and modernization capabilities. Expert insights into AWS, Azure, and GCP transformation strategies for enterprise leaders. -
 February 10, 2026Read in 12 min.
February 10, 2026Read in 12 min.Top 10 Flutter development companies: Entities, ecosystems, and strategic selection
Compare the world’s leading Flutter agencies. Our expert analysis covers the top 10 firms, evaluating their mastery of Dart, Skia performance, and Clean Architecture. -
 February 6, 2026Read in 19 min.
February 6, 2026Read in 19 min.Top 10 React development companies: Architecting high-performance digital products
Top-rated React development companies for your next project. Our expert guide analyzes the best React JS web development agencies on performance, scalability, and tech standards -
 February 3, 2026Read in 24 min.
February 3, 2026Read in 24 min.Web application development companies: How to choose the right partner
Find the right web app development company. Explore services, technologies, engagement models, and 10 expert tips for choosing your strategic development partner. -
 February 3, 2026Read in 11 min.
February 3, 2026Read in 11 min.Top 10 Python Development Companies
Looking for a top Python development company? Compare the industry's leading Python software development agencies. Get insights on pricing, expertise, and how to hire a Python development firm that scales your business. -
 January 27, 2026Read in 15 min.
January 27, 2026Read in 15 min.Top cloud application development companies you should follow
Best Cloud Application Development companies for your project. Compare expertise in AWS, Azure, & GCP. See client reviews, specialization, and costs for top Cloud-Native firms -
 January 23, 2026Read in 21 min.
January 23, 2026Read in 21 min.Dedicated development team model: Definition, benefits, and nuances
Scale your product fast with a Dedicated Development Team. Compare DDT vs. outsourcing, analyze costs, and get a management blueprint for success. -
 January 21, 2026Read in 15 min.
January 21, 2026Read in 15 min.Best energy software development companies to partnership
Top 10 energy sector software development leaders. Learn how to choose the right partner for your renewable energy software project. -
 January 19, 2026Read in 8 min.
January 19, 2026Read in 8 min.The Low-Code Revolution in Oil & Gas: Accelerating Digital Transformation
From real-time well monitoring to automated safety permits - see how low-code applications drive operational efficiency and ESG compliance in the energy sector’s volatile market. -
 January 19, 2026Read in 18 min.
January 19, 2026Read in 18 min.Top 10 desktop application development companies to watch
Compare the world’s best desktop development firms. From legacy modernization to high-performance C++ and cross-platform Electron apps, find your perfect vendor here. -
 December 24, 2025Read in 10 min.
December 24, 2025Read in 10 min.Software development company in Florida: What we do, how we work, and where we add value
Florida's premier custom software partner for enterprise-grade applications. We specialize in fintech, healthcare, and scalable cloud systems. Innovate with Florida experts. -
 December 9, 2025Read in 10 min.
December 9, 2025Read in 10 min.Custom software development for San Diego businesses
Find out about the demands of software development in San Diego and how local companies are adapting to technology needs. -
 December 9, 2025Read in 9 min.
December 9, 2025Read in 9 min.Specifics and perspectives of custom software development in Los Angeles
Find out why choosing a custom software development company in Los Angeles is essential for evolving industries like fintech and healthcare. -
 December 6, 2025Read in 8 min.
December 6, 2025Read in 8 min.Software development in San Francisco: Custom solutions for Area
Find out how software development in San Francisco sets standards in technology and customer satisfaction. -
 November 28, 2025Read in 14 min.
November 28, 2025Read in 14 min.Custom software development in Houston: State and perspectives
Partner with a leading custom software development company in Houston to harness the power of technology for your growth. -
 November 28, 2025Read in 12 min.
November 28, 2025Read in 12 min.Custom software development Dallas businesses need
Find out how a custom software development company in Dallas can elevate your business in a booming tech landscape filled with opportunities. -
 November 27, 2025Read in 11 min.
November 27, 2025Read in 11 min.Software development services in Austin
Find out how a custom software development company in Austin can elevate your business in a booming tech landscape filled with opportunities. -
 November 12, 2025Read in 34 min.
November 12, 2025Read in 34 min.Top FinTech software development companies: The core of modern finance
Compare the top-rated FinTech software developers based on expertise in AI, Blockchain, and compliance. Choose your perfect partner now! -
 November 4, 2025Read in 12 min.
November 4, 2025Read in 12 min.AI in biotech: Application, specifics, and challenges
How AI and Machine Learning are transforming biotechnology, accelerating drug discovery, genome sequencing, and personalized medicine. Learn the applications, challenges, and future. -
 October 28, 2025Read in 20 min.
October 28, 2025Read in 20 min.The best AI development companies in the US
The definitive guide to hiring the best AI development company. See our ranking by MLOps maturity, GenAI expertise, and verified client ROI. Get transparent costs and a partnership blueprint -
 October 20, 2025Read in 16 min.
October 20, 2025Read in 16 min.How to hire the best ReactJS developers in a constantly growing market
Hire the top ReactJS developers. Get pre-vetted, senior React & Next.js engineers matched to your project in 48 hours. Start risk-free -
 October 16, 2025Read in 25 min.
October 16, 2025Read in 25 min.Top 10 AI chatbot development companies
Leading chatbot development companies. Our expert guide helps you choose the best firm for AI chatbot solutions, custom development, and seamless integration -
 October 9, 2025Read in 17 min.
October 9, 2025Read in 17 min.Top biotech software companies: Choosing the right tech partner for life-changing innovations
Leading biotech software companies impacting drug discovery, R&D, and lab operations. See how their innovative platforms are speeding up scientific breakthroughs. -
 September 30, 2025Read in 16 min.
September 30, 2025Read in 16 min.All you need to know about custom software development for small business
Stop wasting time on workarounds! Discover how custom software development empowers your small business with tailored workflows, maximum efficiency, and predictable ROI. -
 September 4, 2025Read in 14 min.
September 4, 2025Read in 14 min.Top 10 leading application modernization companies
Top 10 application modernization companies that can transform your business with cloud, AI, and microservices for agility and growth -
 August 28, 2025Read in 14 min.
August 28, 2025Read in 14 min.Develop once, run everywhere: .NET Core cross-platform development
Struggling with multi-OS development? Discover how .NET empowers you to build versatile, high-performance applications that run seamlessly across Windows, macOS, and Linux with ease. -
 August 21, 2025Read in 14 min.
August 21, 2025Read in 14 min.Why offshore .NET development is the best choice for your business
Struggling with talent shortages or escalating development costs? Explores how embracing offshore .NET development can be the strategic advantage your business needs to build innovative solutions faster and more cost-effectively. -
 August 18, 2025Read in 14 min.
August 18, 2025Read in 14 min..NET vs Java: Comparison, use cases, pros and cons
Unsure whether to use .NET or Java? This guide breaks down their strengths, weaknesses, and ideal applications to help you pick the best technology. -
 August 11, 2025Read in 24 min.
August 11, 2025Read in 24 min.Top 10 Angular development companies to keep an eye on
Leading Angular development companies. Expert Angular developers offering top-tier web application development, consulting, and solutions for your next project. -
 August 7, 2025Read in 15 min.
August 7, 2025Read in 15 min.Hire Angular developers: What you need to know
Need hire Angular developers? Get access to skilled, dedicated Angular teams for your web projects. We provide expert Angular solutions with flexible engagement models. Contact us today! -
 August 1, 2025Read in 9 min.
August 1, 2025Read in 9 min.Why choose Angular for web development
Why Angular is a leading choice for web development. Learn about its powerful features, scalability, and benefits for building robust, high-performance applications. -
 August 1, 2025Read in 12 min.
August 1, 2025Read in 12 min.Hiring .NET developers: Step-by-step guide
Frustrated with the challenges of hiring skilled .NET developers? This article provides a proven framework to help you find, vet, and hire the right talent for your team, avoiding common recruiting mistakes. -
 February 13, 2025Read in 15 min.
February 13, 2025Read in 15 min.What is HMI development, and why is it trending now?
Human-Machine Interface (HMI) development is revolutionizing the way humans interact with machines, driving innovation across industries. -
 December 11, 2024Read in 10 min.
December 11, 2024Read in 10 min.Python vs Java: Key differences, pros, and cons for developers
Key differences between Python and Java, including syntax, performance, and use cases. Find out which language suits your project best -
 October 10, 2024Read in 11 min.
October 10, 2024Read in 11 min.The future of web development: WordPress vs React.js?
Confused between WordPress or React.js? Explore our detailed comparison to find out which platform suits your needs best -
 August 8, 2024Read in 14 min.
August 8, 2024Read in 14 min.AD and Azure AD: What is the difference, and which is better for you?
Differences between Azure Active Directory (AAD) and traditional Active Directory (AD) in this comprehensive comparison. -
 August 5, 2024Read in 15 min.
August 5, 2024Read in 15 min.ESG software development services: Effective ESG software solutions
Innovative ESG software solutions can help your business achieve its sustainability goals. Develop customized software that enhances environmental, social, and governance (ESG) performance, ensuring compliance and driving positive impact -
 July 31, 2024Read in 7 min.
July 31, 2024Read in 7 min.Benefits of Azure Active Directory
Key benefits of Azure Active Directory(AD), including enhanced security, simplified management, and cost savings for your business -
 April 22, 2024Read in 12 min.
April 22, 2024Read in 12 min.Software modernization: What is it & why it matters
Discover the essence of software modernization and its pivotal role in contemporary software development. Uncover why it's crucial. -
 April 22, 2024Read in 20 min.
April 22, 2024Read in 20 min.Legacy app modernization: A comprehensive guide
Revitalize your business with our guide on legacy application modernization. Transform your legacy systems to make them more efficient and innovative. -
 April 22, 2024Read in 16 min.
April 22, 2024Read in 16 min.Digital product design: What is it and why you need it
Unlock innovation with expert digital product design insights. Explore the latest trends and strategies for creating exceptional user experiences. -
 April 21, 2024Read in 11 min.
April 21, 2024Read in 11 min.Healthcare product design: Tips for app development success
Explore the art of healthcare product design in our latest blog post. Discover how innovative design principles are shaping the future of medical solutions -
 April 18, 2024Read in 9 min.
April 18, 2024Read in 9 min.Azure app modernization: Benefits of migrating to Microsoft
Key benefits of Azure app modernization and how migrating to Microsoft can enhance performance, scalability, and compliance -
 March 11, 2024Read in 12 min.
March 11, 2024Read in 12 min.How to choose asset management software for oil and gas in 2026
Explore more ways to optimize operations and streamline processes in oil and gas. Follow our tips to choose the best-fit assent management software in 2026 -
 March 11, 2024Read in 13 min.
March 11, 2024Read in 13 min.AI software development for oil and gas: A comprehensive guide
Explore the transformative power of artificial intelligence software development for oil and gas and the practices of global industry leaders in our blog. -
 March 11, 2024Read in 19 min.
March 11, 2024Read in 19 min.Cloud application modernization: How to improve your app
Cloud application modernization makes app more competitive and business more profitable. The key strategies, tips, and its benefits — in this article! -
 March 11, 2024Read in 12 min.
March 11, 2024Read in 12 min.Enterprise application modernization: Revolutionize your business
Future-proof your business with our guide to enterprise app modernization. Learn strategic approaches, key technologies, and best practices for legacy system transformation and enhanced agility -
 March 11, 2024Read in 12 min.
March 11, 2024Read in 12 min.LIMS integration: Benefits & how it works
Can LIMS integration be called a CRM for laboratories? What to keep in mind during LIMS software development and integration? Find out more in our article. -
 March 11, 2024Read in 11 min.
March 11, 2024Read in 11 min.Active directory integration: What is it & how to do it effectively
Discover seamless Active Directory integration strategies in our latest blog post. Optimize user management with the Blackthorn Vision team! -
 March 5, 2024Read in 15 min.
March 5, 2024Read in 15 min.Mobile app UX design: Basics that will improve user experience
Mobile app UX design differs from the web. Explore these differences, the process, and the main pitfalls with our experts in this article. -
 March 5, 2024Read in 11 min.
March 5, 2024Read in 11 min.HIPAA compliance checklist for healthcare software development 2026
Check the updated HIPAA security guidelines to ensure the safety and privacy of patients' data, it is important to adhere it when creating applications -
 March 5, 2024Read in 9 min.
March 5, 2024Read in 9 min.How to use business process automation to improve oil and gas production
Discover how business process automation can help optimize oil and gas production and improve your bottom line. -
 March 3, 2024Read in 14 min.
March 3, 2024Read in 14 min.Desktop to web migration: everything you need to know
Planning a desktop to web migration? Get essential insights on strategy, technical challenges, approaches, and how to successfully modernize your legacy application. -
 March 3, 2024Read in 11 min.
March 3, 2024Read in 11 min.The process of application migration to the cloud: stages, approaches, and tools
Find out how to effectively migrate your legacy system and data to the cloud without disrupting your business processes. -
 March 3, 2024Read in 16 min.
March 3, 2024Read in 16 min.Benefits of outsourcing software development
Key advantages of outsourcing software development for businesses. Learn how outsourcing can reduce costs, increase efficiency, and provide access to specialized expertise -
 March 3, 2024Read in 13 min.
March 3, 2024Read in 13 min.Boosting cloud security in healthcare with Azure Cloud Services
Explore the most common challenges in the cloud security of healthcare organizations and discover our tips on eliminating them efficiently. -
 March 3, 2024Read in 19 min.
March 3, 2024Read in 19 min.Healthcare app design: how to create a great user experience
Struggling with medical app UX? Get insights into user-centered design, crucial security measures, and future trends to create impactful healthcare applications. -
 March 3, 2024Read in 16 min.
March 3, 2024Read in 16 min.MVP vs. prototype in startup software development: what’s the difference?
Crucial differences between MVP and Prototype in startup software development. Learn how Blackthorn Vision leverages both to build successful products, reduce risk, and accelerate your time-to-market -
 March 3, 2024Read in 12 min.
March 3, 2024Read in 12 min.How to build a custom EHR solution: tips for decision makers
We can augment your talent pool with dedicated developers proficient in healthcare business automation. Check the success stories from our clients. -
 March 3, 2024Read in 7 min.
March 3, 2024Read in 7 min.What is software as a medical device and why it matters for the healthcare industry
From developing SaMD and SiMD to building efficient EHR systems, we unleash the value of business process automation for healthcare providers. -
 March 3, 2024Read in 6 min.
March 3, 2024Read in 6 min.An overview of medical biotechnology in 2026 and beyond
We offer a full cycle of software development for leading biotech companies - from idea visualization to building an MVP and fully-fledged product. -
 March 3, 2024Read in 9 min.
March 3, 2024Read in 9 min.Smart farming: agricultural technology of the future
We have expertise in data analytics, AI, and Machine Learning to build game-changing software tailored for your agricultural business. -
 March 3, 2024Read in 7 min.
March 3, 2024Read in 7 min.BV people: a talk with Head of HR and recruitment in Blackthorn Vision
BV people: a talk with the Head of HR and Recruitment on candidate selection, the company's ideals, and the current state of the Ukrainian IT industry. -
 March 3, 2024Read in 9 min.
March 3, 2024Read in 9 min.What is robotic process automation and how it changes the travel and hospitality industry
How does RPA work and, most importantly, how to utilize it in your travel and hospitality business? Find out in our new article now. -
 March 3, 2024Read in 12 min.
March 3, 2024Read in 12 min.An overview of agricultural biotechnology in 2026
We cooperated with agricultural biotechnology industry leaders to design software that helps scientists and farmers automate and optimize all processes. -
 March 3, 2024Read in 10 min.
March 3, 2024Read in 10 min.Everything you need to know about Microsoft Azure: benefits, use cases, applications
Microsoft Azure is a leading cloud service provider that offers numerous opportunities for businesses to optimize and secure their operations and services. -
 March 3, 2024Read in 10 min.
March 3, 2024Read in 10 min.Smart manufacturing technology and trends for 2026 and beyond
Stay updated on the latest manufacturing technology trends, that drives innovation, efficiency, and growth in the industry to boost your project. -
 March 3, 2024Read in 8 min.
March 3, 2024Read in 8 min.How to choose and manage your dedicated development team
While there are many benefits of working with dedicated software development teams, it’s not a universal solution. Discover why it is so. -
 March 3, 2024Read in 8 min.
March 3, 2024Read in 8 min.What is the best cloud deployment model? Types of cloud computing that will benefit your business
With the guidance of our post, you can better understand various cloud computing deployment strategies. Examine cloud solutions for your company's needs. -
 March 3, 2024Read in 10 min.
March 3, 2024Read in 10 min.Offshore vs. Nearshore outsourcing: what’s best for your business?
What is the difference between the three outsourcing types, and which one is better for your business? Please read our article to find out! -
 March 3, 2024Read in 14 min.
March 3, 2024Read in 14 min.How to develop a medical app for doctors: everything you need to know
The mobile health industry is one of the most rapidly growing segments worldwide. Learn more about the mHealth industry in our new article. -
 March 3, 2024Read in 14 min.
March 3, 2024Read in 14 min.Business analyst: a leading player in your software development team
Your guide to the Business Analyst's vital role in software development teams, including Agile practices, key responsibilities, techniques, and delivering real business value. -
 March 3, 2024Read in 9 min.
March 3, 2024Read in 9 min.Hyperautomation – the future of business processes
Now business processes - Hyperautomation are increasingly not following stable and predictable scenarios. It creates a need for a new type of automation. -
 March 3, 2024Read in 6 min.
March 3, 2024Read in 6 min.The future of Oil and Gas: industry trends and software solutions
Keep up to date on the most recent oil and gas the industry trends, which are driving modifications in technology, sustainability, and energy exploration. -
 March 3, 2024Read in 6 min.
March 3, 2024Read in 6 min.What is an MVP, and why is it necessary? Minimum viable product examples
Even if you have just a basic vision of what your app should do, we will develop a presentable product that you can pitch to investors. -
 March 3, 2024Read in 14 min.
March 3, 2024Read in 14 min.Top 5 soft skills to work in it successfully and resources to develop them
Are soft skills the new hard skills? Can you make a successful career in IT if you are not an effective communicator or lack creativity? -
 March 3, 2024Read in 5 min.
March 3, 2024Read in 5 min.Mobile app development: Xamarin.Forms — a cross-platform solution that responds to modern challenges
When it comes to mobile development, there is a wide variety of solutions. Xamarin.Forms is a cross-platform solution that responds to modern challenges. -
 February 27, 2024Read in 8 min.
February 27, 2024Read in 8 min.Top 10 programming languages of the future for web and mobile app development
Let’s have a look at the most popular programming languages that may become your business workhorse. -
 February 6, 2024Read in 16 min.
February 6, 2024Read in 16 min.Pharmaceutical software development: Unleashing pharma innovation
Explore the future of pharmaceutical software development: innovative solutions revolutionizing healthcare efficiency & precision.